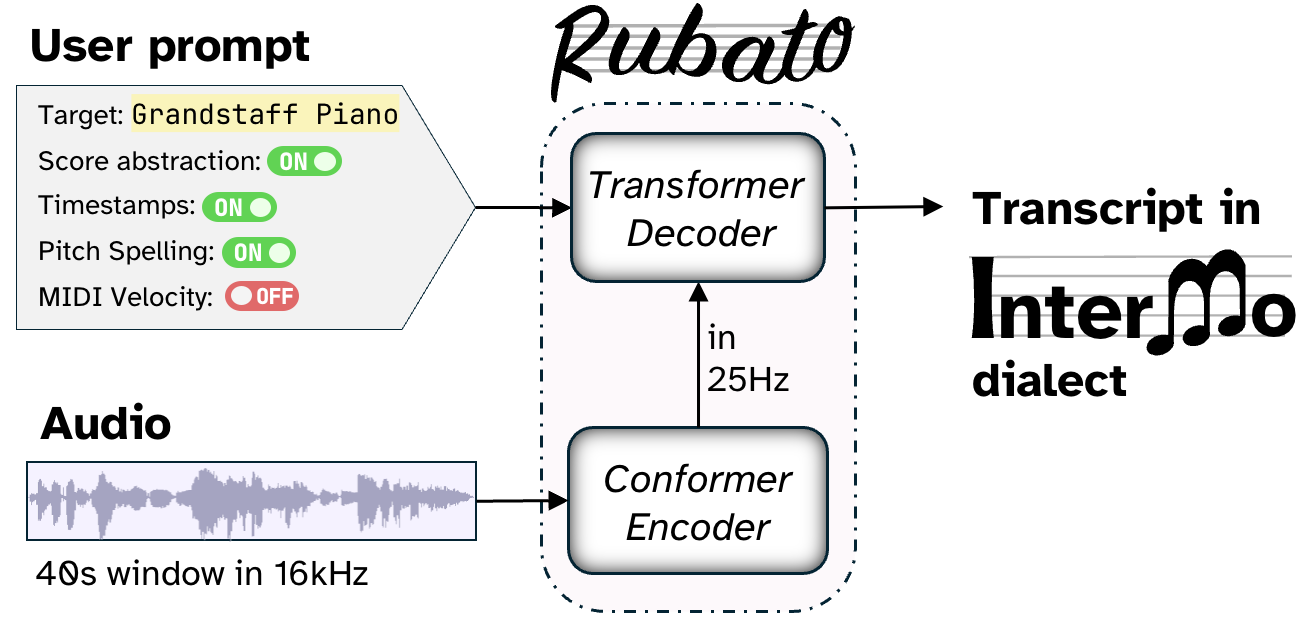
Rubato is a small audio language model that listens to music and writes out the score — note by note, beat by beat, synchronized to the audio.
It is powered by InterMo, a new symbolic music language that encodes notation and timing in a single sequence, so the model can generate both at once.
The result: you can follow the score in sync with the recording and feel the rubato — the expressive timing that gives each performance its character.
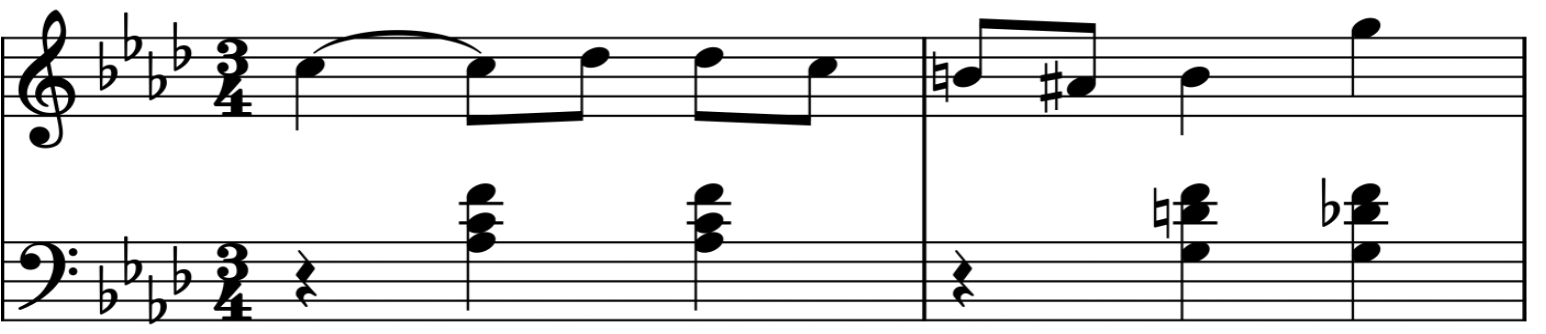
Piano transcription
Rubato is trained on piano audio. The scores you see here are generated entirely from the audio signal — no human editing, no MIDI input.
Zero-shot piano reduction
For orchestral, ensemble, and pop recordings, Rubato produces a piano reduction without any additional training on non-piano audio. It maps what it hears onto a grand staff, giving you a readable two-hand score of music it was never trained on.
© Nazif Can Tamer. This interface demonstrates one of many possible applications of InterMo generation. Unauthorized commercial use is prohibited and may be traced through unique identifiers embedded in each deployment. Free for open science and non-commercial use in education.